Reel Wall, v1 -> v2
An account behind a VPN, Raspberry Pi, and an agent scrolling for no one.
The account never sleeps and never blinks and never wants a thing. It lives behind a VPN on a Raspberry Pi on my home network, and the only person who ever touches it, me, touches it by typing instructions to an Artificial Agent. When it opens Instagram it cannot even watch the video. A grey panel fills the phone-shaped frame: Sorry, we're having trouble with playing this video. The scraper sits there, logged in, blind, while the feed plays to nobody.
The blind account reads more of the algorithm than I do when I scroll for reel. It is not trying to act like me.
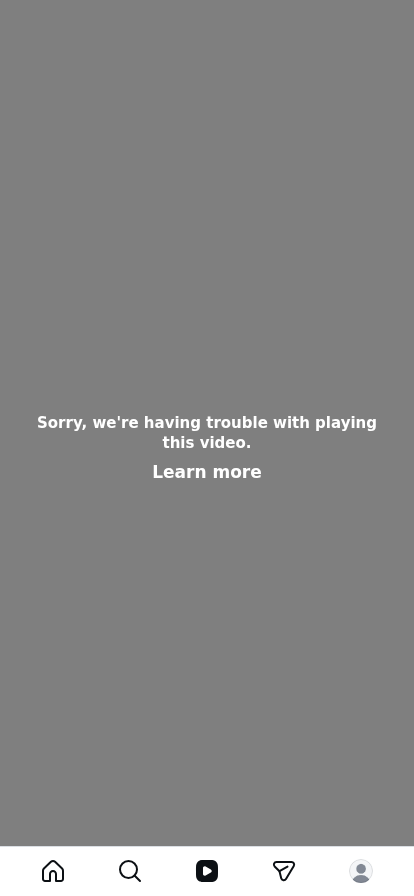
What the scraper sees: logged in, Instagram's nav bar still across the bottom, yet unable to play the H.264 video, so a grey panel reports trouble while the recommendation data arrives over the network instead.
The most honest map came from a refusal
Instagram guards the feed. Every off-the-shelf tool I tried, instaloader and yt-dlp and gallery-dl, hit a wall the moment it logged in. The next idea, drive a real browser but hide it inside a virtual display and screen-record the result, produced a column of blank frames, because the hidden browser refused to play the video at all. Each fix acted as an attempt to imitate a person harder than the last, and each one failed harder as well.
The approach that worked gave up impersonation altogether. A single ordinary load of the Reels feed makes Instagram hand the browser a tidy ordered list of what to play next, every entry tagged, in Instagram's own words, recommended_clips_chaining_model. The chain comes pre-written. I do not reconstruct the journey through fake swipes; I read the journey straight off the network while the video plays for no one.
What sits behind that tag took some reading. Meta describes Explore, the engine underneath, as a funnel that narrows billions of candidate clips down to the few dozen you see, in four passes: retrieval, two rounds of ranking, then a final reranking. Retrieval runs on "two-tower" neural nets that turn both you and each reel into a long string of numbers, an embedding, and count a reel relevant when its numbers sit close to yours. The heavy ranking pass scores each survivor with what the engineers call a value model, a weighted sum of the odds you click and the odds you like and the odds you tap "see less." For Reels in particular, Adam Mosseri named watch time and sends and likes as the signals that carry the most weight.
The last pass interests me most. After the math picks winners, a reranking layer reshuffles them by hand-written rules, and Meta spells out one example outright: "Do not show items from the same authors in a sequence." Diversity comes engineered in, making the feed wander on purpose.
An agent scrolling for no one
Instagram now ships an auto-scroll setting that runs reels one after another for "chronic reel watchers," no thumb required. My account takes the same logic to its rational end, with no thumb, no eyes, no chronic watcher--no watcher at all, in fact. It scrolls for data alone and throws away any form spectacle.
I wrote a work text for the piece before I understood any of the engineering: VPN algorithm pure and virgin, no human eyes or needs or wants, no impurities, no indignities, only scroll, wait 5 seconds, scroll. She's mapped my pilgrimage to the absolute mean.
Me and Claude <3, a little insane
The whole apparatus, the scraper and the database and the clustering and the two public websites, came out of me and an AI, mostly. I cannot write the code. I describe what I want, in plain sentences, and Claude writes it, and I run it, and when it breaks I describe the break and we go again. I feel like a magician pulling a working system out of a hat.
The closest honest analogy I can reach hovers between the job of a translator and a director. Translator: I speak intent and the model speaks Python and whatever survives the crossing, crosses. Director: I never touch the camera, but the film carries my decisions. Both at once, probably, and neither quite right, because a translator and a director both command the craft they delegate, in theory, and I do not.
Once the documents existed I handed the code to a friend who used to engineer software at a major company, who will remain unnamed for now. He pushed a few changes and sent back this note. "Honestly impressive what you were able to set up here, even with Claude," he wrote, then naming the flaw: "Claude loves to reimplement things, so there are multiple definitions of the same concept scattered around, meaning behavior is a bit different depending on which exact thing you're calling. It also likes to write things from scratch, so I started replacing unnecessary code with more standard libraries."
There's something to that feedback, for me. As he noted, I built a thing that works and that a trained engineer can read the seams of in an afternoon. But the model writes from scratch what a code-fluent person would build through a library, and scatters three versions of one idea throughout the code, and I lack the fluency to catch it. The idea of reimplementation seems to sit well with the data I've (we've?) collected so far from Instagram: there is no direct formula, only a series of semi-tangible connections which then await to be classed by an actual process of reasoning.
Two ways to sort a feed
The map went through two schema, which for now I've kept alive online in tandem. The first version imposes order from outside. It reads each reel's caption through a language model, falls back to reading the thumbnail through an image model when the caption shrinks to three emoji, and sorts everything into clean topic islands: dogs, hiking, food, poetry. It answers a question of: what content be here.
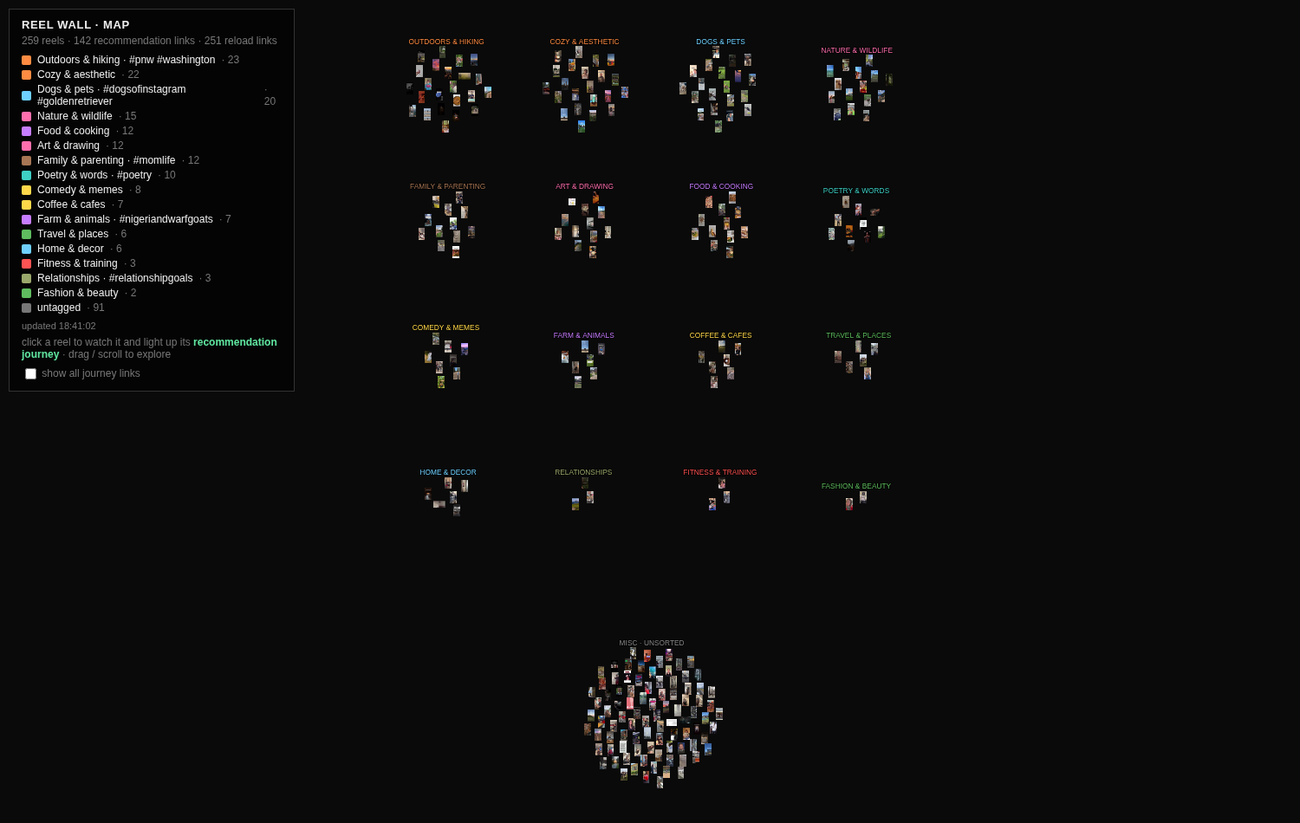
V1 sorts the reels into named topic islands by reading captions, and thumbnails where the caption fails, through AI models. The labelled clusters answer "what kind of content live here."
The image model has a name, "CLIP", and it works by dropping the thumbnail and a short list of words I choose into one shared space, then picks whichever word sits closest to the picture, so a captionless dog reel lands under dogs. Which means, I think, that the categories come from me and not from the reels: CLIP does not find topics, it matches the ones I hand it. V1's order arrives from outside down to the labels I happened to offer.
The second version rejects advance classification. It builds the map out of the recommendation links themselves, pulls reels that lead into each other close together, and lets the categories surface from the shape of the traffic. The layout stops illustrating the journey and becomes the journey.

V2 builds the map from the recommendation links themselves. Each green line marks an experienced what-leads-to-what chain, so the layout becomes the algorithm's path rather than a picture I've laid atop it.
To find those emergent categories I leaned on three different community-detection algorithms, and the live map lets you flip between them; maybe there is something to the disagreement between them. Louvain and Leiden both chase "modularity," a score that rewards groups stitched more densely inside than between; Leiden simply refines Louvain toward the same goal, which explains why the two mostly agree. Infomap asks a different question. It models a random walker stepping link to link, hunts for the regions the walker keeps getting caught in, and scores a grouping by how short a code it would take to describe the walk. I've come to understand it as: modularity asks what clumps, while flow asks where the current ends up pooling.



Louvain, Leiden, Infomap: one graph, three algorithms, three readings. Louvain finds eighteen communities and Leiden sixteen, balanced and mid-sized; Infomap, following the flow of a random walker, pours two hundred and six of the reels into a single basin and leaves a handful of crumbs around it. For now, its good to leave something to be refined.
Vague labels and what they count for
A few communities name themselves cleanly, a dogs cluster, a hiking cluster. Others come back as "happened · bath · starts" or "far · spots · roadtrip," word-salad labels that describe no subject at all. My first instinct blamed my labeling code, but maybe not just that.
The graph is relatively sparse, still: each reel connects, on average, to fewer than three others, close to a single thread. Community detection on a sparse graph sits near a hard wall, as mathematicians have located. Below a certain density a network grows statistically indistinguishable from a random one, and no algorithm, no matter how clever, can recover real communities from it, because real communities have not formed yet. The vague labels do not record my failure. They record emergence caught too early, before enough threads cross for a shape to hold.
Deleuze and Guattari set the rhizome, a structure that connects any point to any other and grows from no root, against arborescence, the tidy branching tree they treat as the West's default picture of knowledge. My second map grows rhizomatically: any reel can reach any other, nothing sits at the root, and the whole tangle resists sorting into a clean trunk of topics. The cross-topic drift I keep trying to tidy traces the same impulse Meta builds in with its "do not repeat an author" rule. My annoyance, I think, stems from how badly I want to draw a tree from a thing that grows as a tangle. I'm not even sure unnamed collaborator can untangle this algorithmic mess.

Click any reel and its own chain surfaces through the tangle while the rest dims.
What the tangle wants next
The tangle wants density, so I collect more, and watch whether the communities sharpen or stay fuzzy as the threads multiply, because the sparsity, not the code, sets the ceiling. I still do kind of want to try naming the emergent communities by what their reels visually show; I wonder if, by handing the thumbnails back to the image model, I can create some reason from these seemingly-irrational flow-built categories. I also am continuing to think about how to keep the bronze/pewter reliquaries and the live maps pointed at each other. Devotional Object and Working Diagram, tracing one pilgrimage.
Sources
Vladislav Vorotilov & Ilnur Shugaepov, "Scaling the Instagram Explore recommendations system," Engineering at Meta, 2023.
"How the Instagram Algorithm Works," Buffer (Mosseri's 2025 Reels ranking signals).
"Instagram Is Testing a New Auto-Scroll Feature for Chronic Reel Watchers," Beebom.
Santo Fortunato & Darko Hric, "Community detection in networks: A user guide," Physics Reports, 2016 (sparse-network detection limits).
Gilles Deleuze & Félix Guattari, A Thousand Plateaus, 1980 (English trans. Massumi, 1987).
Reel Wall live maps: reels.jjhellerman.xyz and reels-v2.jjhellerman.xyz.